
Setting up a project that runs in a web server (consider a traditional server like an AWS EC2 instance) requires you to deploy your code and configure the application. Doing this once may not be a big task but doing it continuously is not. Not to mention it will get impractical. Especially if it’s a project that you work on and maintain actively.
Setting up a good way to deploy your application is one of the key characteristics of a successful development setup. Ideally, your project should have an automated way to deploy, and roll back changes.
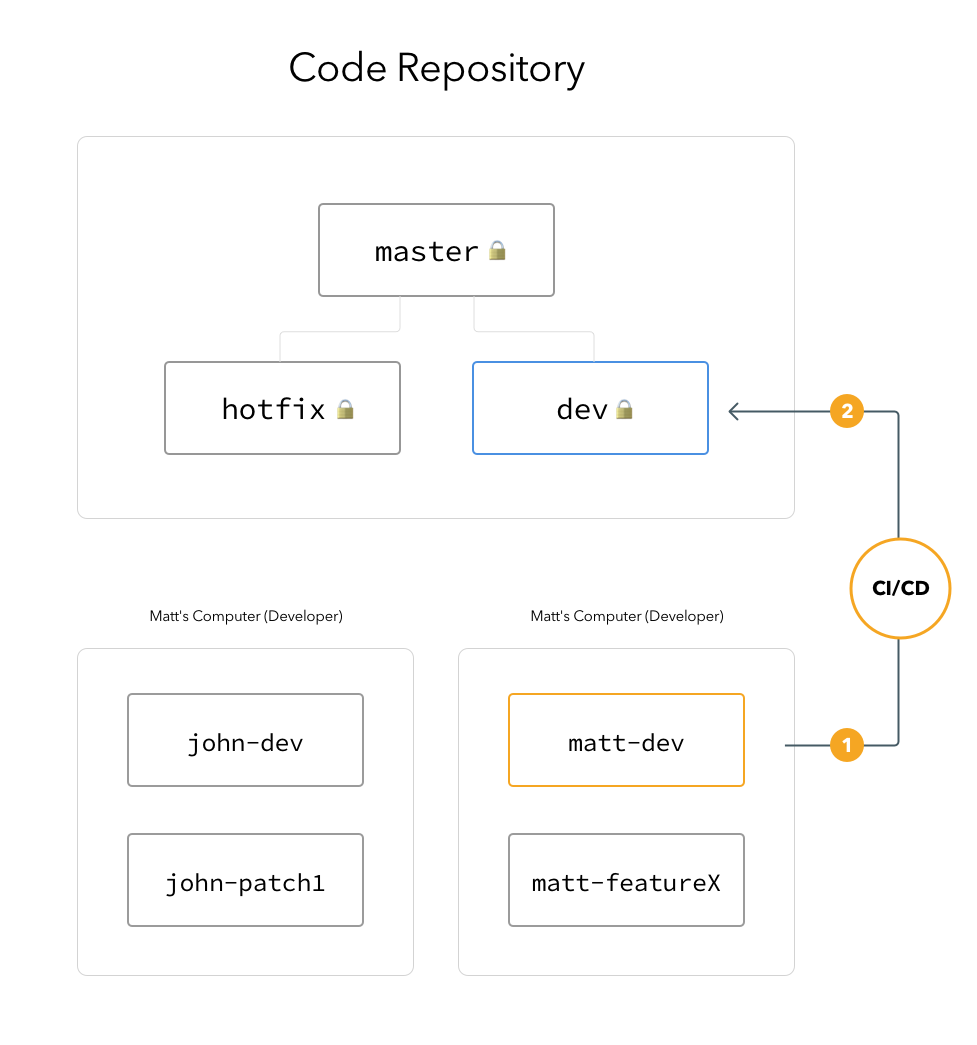
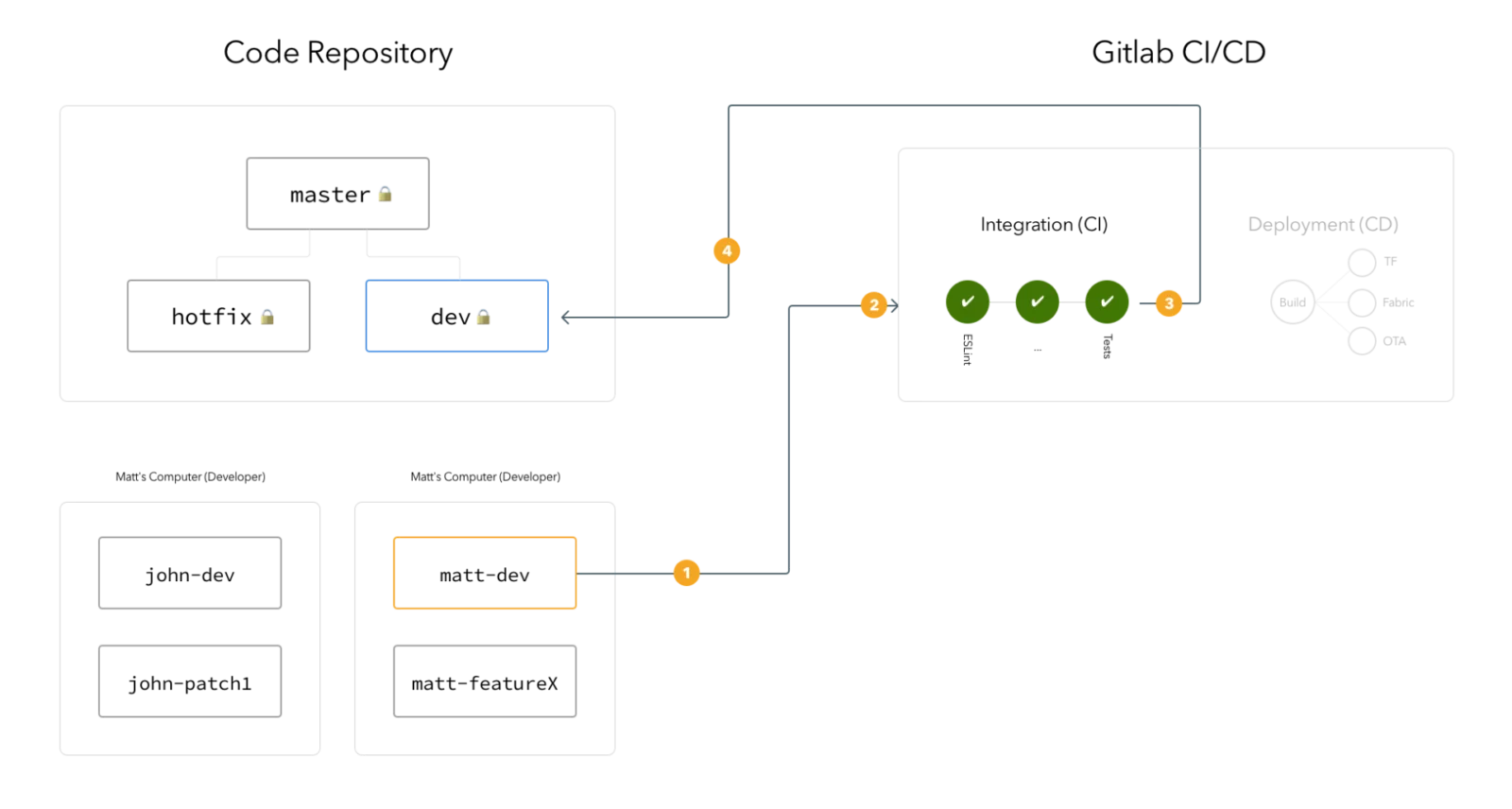
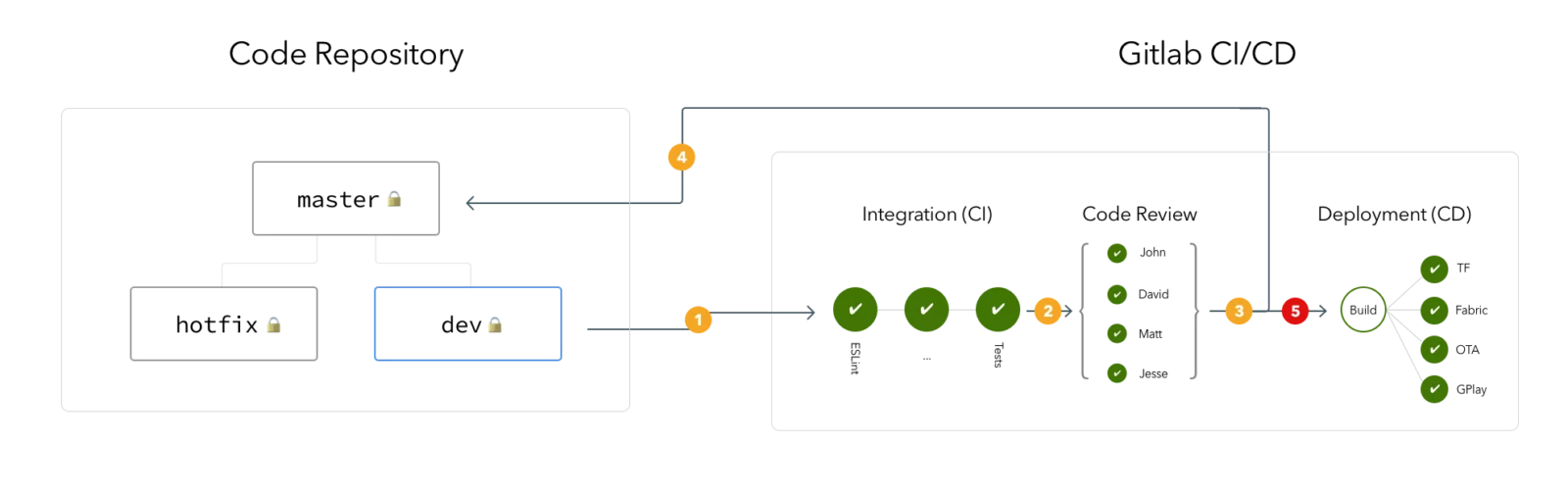
It makes a lot of sense of to use version control systems as the base of deployments. VCS systems are about how code changes are tracked by individual developers, comes together and merges back to the main branches. It perfectly fits well to have the capabilities to track deployments to these changes too.
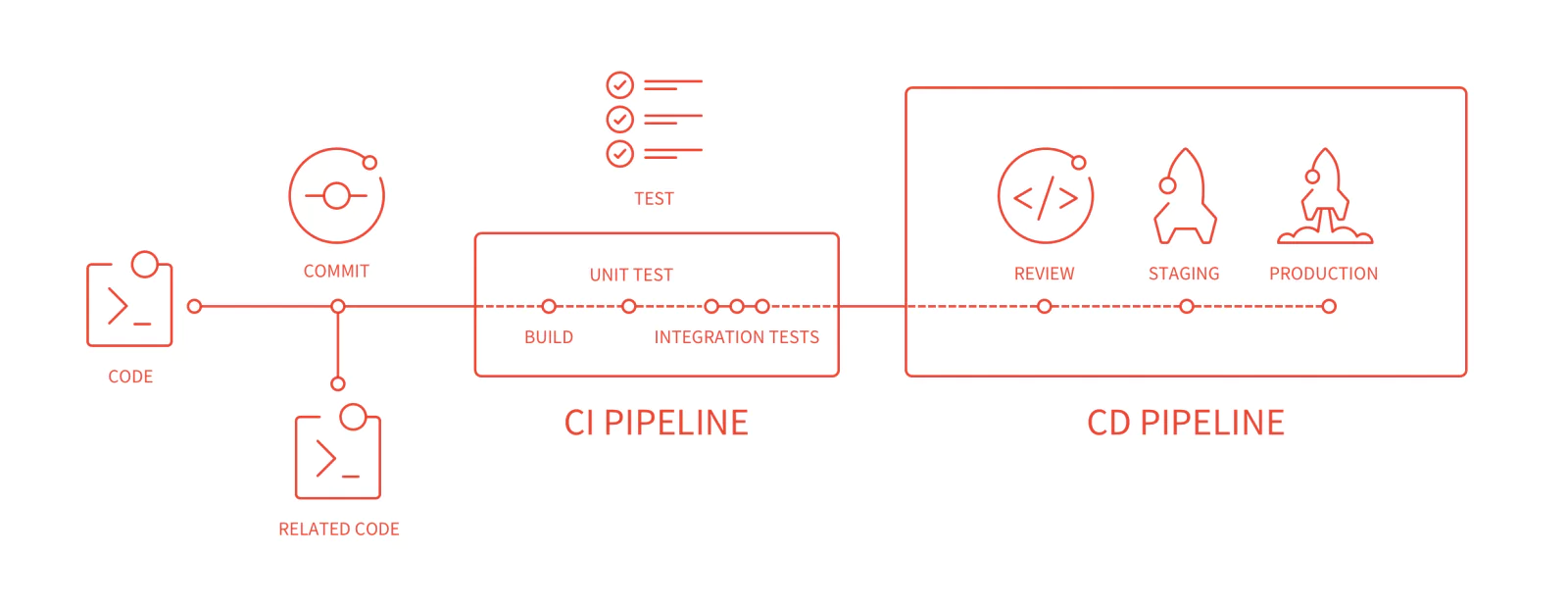
The VCS services like Github and Gitlab now come with powerful CI/CD pipelines supports these use cases almost out of the box.
There are also many ways to achieve what I’m going to describe in this post. But I take this as my bare minimum, plain and simple way to deploy code and perform simple tasks to restart my application automatically as part of my code workflow.
We will be using SSH and RSYNC to update your code remotely, then update the changed/added/deleted files in your target folder then restart your application if needed.
In a PHP-based project, updating files would be enough because apache will be running the scripts in every single request unless you are using a caching module – which even comes with an automatic cache refresh if the file is changed.
If you are deploying a NodeJS (or similar) app that needs to be re-started, then we’ll use remote SSH command to perform a restart operation from your CI/CD pipeline.
Let’s jump right in the .gitlab-ci.yml example and I will point out the key areas in this template.
image: node
stages:
- deploy
variables:
npm_config_cache: "$CI_PROJECT_DIR/.npm"
cache:
key: ${CI_COMMIT_REF_SLUG}
paths:
- .npm
production_deployment:
stage: deploy
image: alpine
only:
- master
before_script:
- apk update
- apk add openssh git curl rsync
- git checkout -B "$CI_BUILD_REF_NAME" "$CI_BUILD_REF"
variables:
DOCKER_DRIVER: overlay
SERVER_NAME: "my-server-name"
CONNECTION_STR: "[email protected]"
ENVIRONMENT: "production"
PROJECT_NAME: "myproject"
SLACK_CI_CHANNEL: "#ci-myproject"
RSYNC_EXCLUDES: "--exclude 'storage' --exclude '.env' --exclude 'node_modules' --exclude 'keys' --exclude '.git' --exclude '.yarn-cache'"
RSYNC_BEFORE_HOOK: "mkdir -p $DEPLOY_PATH && rsync"
DEPLOY_PATH: "/srv/data/deploy/${PROJECT_NAME}/production"
SERVE_PATH: "/srv/data/www/${PROJECT_NAME}/production"
PRIVATE_KEY: $SSH_PRIVATE_KEY_DEPLOYER
script:
- mkdir -p ~/.ssh
- 'which ssh-agent || ( apk add --update openssh )'
- eval "$(ssh-agent -s)"
- echo "${PRIVATE_KEY}" | tr -d ' ' | base64 -d | ssh-add -
- '[[ -f /.dockerenv ]] && echo -e "Host *\\n\\tStrictHostKeyChecking no\\n\\n" > ~/.ssh/config'
- ssh "$CONNECTION_STR" "mkdir -p $SERVE_PATH $DEPLOY_PATH;";
- rsync -avzqR --rsync-path="$RSYNC_BEFORE_HOOK" $RSYNC_EXCLUDES --delete -e 'ssh' ./ "$CONNECTION_STR:$DEPLOY_PATH";
- ssh "$CONNECTION_STR" "cd $DEPLOY_PATH; rsync -avqR --delete ${RSYNC_EXCLUDES} ./ ${SERVE_PATH}";
- ssh "$CONNECTION_STR" "cd ${SERVE_PATH}; npm install --production";
- ssh "$CONNECTION_STR" "if forever list | grep 'production/server_run.js'; then forever stop ${SERVE_PATH}/server_run.js; fi; forever start --workingDir ${SERVE_PATH} ${SERVE_PATH}/server_run.js"
- 'cd $CI_PROJECT_DIR && sh ./scripts/notify_slack.sh "${SLACK_CI_CHANNEL}" ":rocket: Build on \\`$ENVIRONMENT\\` \\`$CI_BUILD_REF_NAME\\` deployed to $SERVER_NAME! :white_check_mark: Commit \\`$(git log -1 --oneline)\\` See <https://gitlab.com/myproject/$(basename $PWD)/commit/$CI_BUILD_REF>"'
environment:
name: production
url: <http://myproject.com>
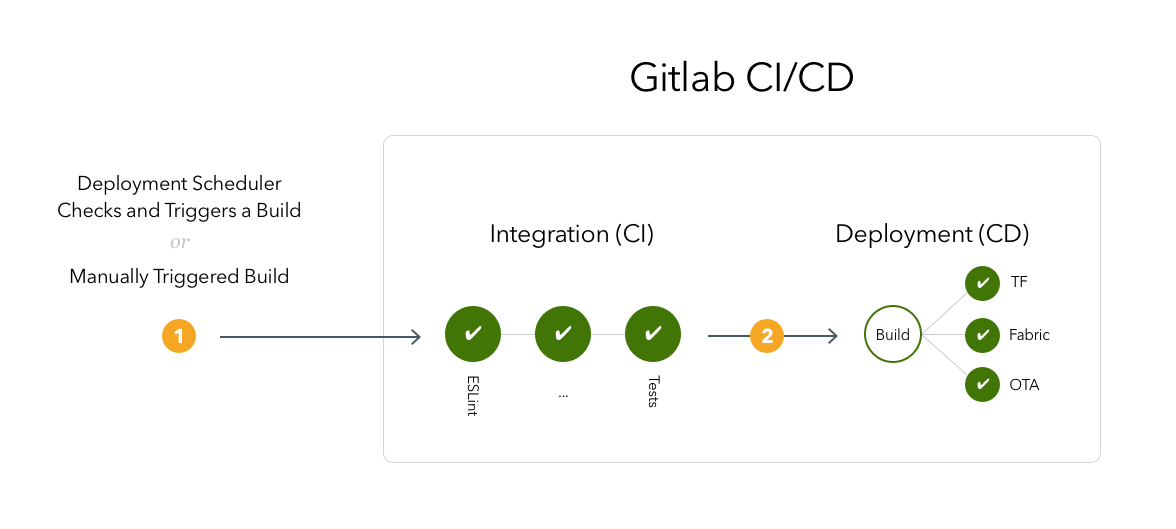
Essentially we need to do:
- Upload (or update) the files in the server
- Restart the application (if needed)
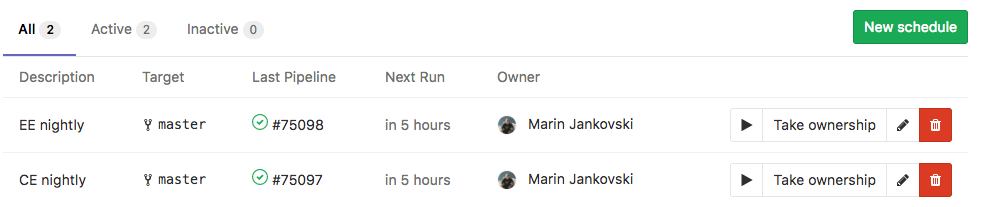
You get a deployment log like this:
Running with gitlab-runner 15.4.0~beta.5.gdefc7017 (defc7017) on green-4.shared.runners-manager.gitlab.com/default ntHFEtyX section_start:1664673660:prepare_executor Preparing the "docker+machine" executor Using Docker executor with image alpine ... Pulling docker image alpine ... Using docker image sha256:9c6f0724472873bb50a2ae67a9e7adcb57673a183cea8b06eb778dca859181b5 for alpine with digest alpine@sha256:bc41182d7ef5ffc53a40b044e725193bc10142a1243f395ee852a8d9730fc2ad ... section_end:1664673666:prepare_executor section_start:1664673666:prepare_script Preparing environment Running on runner-nthfetyx-project-17714851-concurrent-0 via runner-nthfetyx-shared-1664673617-f4952085... section_end:1664673667:prepare_script section_start:1664673667:get_sources Getting source from Git repository $ eval "$CI_PRE_CLONE_SCRIPT" Fetching changes with git depth set to 50... Initialized empty Git repository in /builds/amazingproject/website/.git/ Created fresh repository. Checking out 7ab562d5 as staging... Skipping Git submodules setup section_end:1664673681:get_sources section_start:1664673681:step_script Executing "step_script" stage of the job script Using docker image sha256:9c6f0724472873bb50a2ae67a9e7adcb57673a183cea8b06eb778dca859181b5 for alpine with digest alpine@sha256:bc41182d7ef5ffc53a40b044e725193bc10142a1243f395ee852a8d9730fc2ad ... $ apk update && apk add git curl rsync openssh openssh-client python3 fetch https://dl-cdn.alpinelinux.org/alpine/v3.16/main/x86_64/APKINDEX.tar.gz fetch https://dl-cdn.alpinelinux.org/alpine/v3.16/community/x86_64/APKINDEX.tar.gz v3.16.2-221-ge7097e0782 [https://dl-cdn.alpinelinux.org/alpine/v3.16/main] v3.16.2-229-g1f881aca9b [https://dl-cdn.alpinelinux.org/alpine/v3.16/community] OK: 17033 distinct packages available (1/33) Installing ca-certificates (20220614-r0) . . . (33/33) Installing rsync (3.2.5-r0) Executing busybox-1.35.0-r17.trigger Executing ca-certificates-20220614-r0.trigger OK: 78 MiB in 47 packages $ git clone https://github.com/MestreLion/git-tools.git && git-tools/git-restore-mtime Cloning into 'git-tools'... 12,931 files to be processed in work dir Statistics: 0.57 seconds 13,151 log lines processed 59 commits evaluated 2,204 directories updated 12,931 files updated $ which ssh-agent || ( apk add --update openssh ) /usr/bin/ssh-agent $ eval "$(ssh-agent -s)" Agent pid 54 $ echo "${PRIVATE_KEY}" | tr -d ' ' | base64 -d | ssh-add - Identity added: (stdin) ((stdin)) $ mkdir -p ~/.ssh $ [[ -f /.dockerenv ]] && echo -e "Host *\n\tStrictHostKeyChecking no\n\n" > ~/.ssh/config $ ssh "$CONNECTION_STR" "mkdir -p $DEPLOY_PATH;"; Warning: Permanently added '199.192.23.254' (ED25519) to the list of known hosts. $ echo "--------> Copy latest codebase to remote" --------> Copy latest codebase to remote $ eval "rsync -avzqR --rsync-path='$RSYNC_BEFORE_HOOK' $RSYNC_EXCLUDES --delete -e 'ssh' ./ '$CONNECTION_STR:$DEPLOY_PATH'" $ ssh "$CONNECTION_STR" "find $DEPLOY_PATH -type d \( -path $DEPLOY_PATH/assets/uploads -o -path $DEPLOY_PATH/application/logs \) -prune -o -exec chmod og-w {} \;" $ cd $CI_PROJECT_DIR && sh ./scripts/notify_slack.sh "${SLACK_CI_CHANNEL}" ":rocket: Build on \`$ENVIRONMENT\` \`$CI_BUILD_REF_NAME\` deployed to $SERVER_NAME! :white_check_mark: Commit \`$(git log -1 --oneline)\` See <https://gitlab.com/amazingproject/website/commit/$CI_BUILD_REF>" % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0 100 427 0 2 100 425 15 3218 --:--:-- --:--:-- --:--:-- 3259 oksection_end:1664673757:step_script section_start:1664673757:cleanup_file_variables Cleaning up project directory and file based variables section_end:1664673758:cleanup_file_variables Job succeeded
It runs fast, is almost universal and applicable to any type of codebase, and is extendable. If you need to restart your application by either using process managers or full daemon restart, you can add a new command and use the ssh lines that we remote-execute a command on the server.
Create and use a limited-permission deployer user for better security
A good rule of thumb is to set up a “deployer” user on the server, have the smallest possible permissions to the user, and have the target folder write access so these commands run properly. There is even a way to give sudo rights for specific commands if you really need to execute something with root permissions, without having a full sudo-enabled user account.
Even simpler deployment
Maybe RSYNC is even more complex for your needs. Maybe all you need is to pull the repo on your server initially, and in each deployment run “git pull”. You can simplify this script to get rid of all rsync parts and only have a remote SSH command runs that.








 This is a short explanation of a feature I really like about github and now it’s imitated in bitbucket. Essentially allows you to host a static site under your account.
This is a short explanation of a feature I really like about github and now it’s imitated in bitbucket. Essentially allows you to host a static site under your account.