Many years ago, we used IronWorker as our worker running, management service. We were also delegating all infrastructure resources for the workers that required more and more resources as we scaled our app back then. It was great to have the workers separated from our main applications (API, website…).
Just to give you context, the workers - or background scripts - are generally independent and isolated scripts that run in their own schedules to do one and only one type of task - like sending birthday emails, or calculating an index that will be used for a function on the website that is used frequently. Each worker/script has separate schedules. Some run once a day (generally runs nightly), or some run every hour or some run even more frequently like every 5 minutes or so. There are also workers that are designed to always-run, but these tasks also can be designed and coded as scripts that can run in batches and scheduled accordingly. Workers are mostly packaged, all dependencies included scripts that only require a runtime and its external dependencies like database connection, etc…
We used different solutions in different projects over the years along with cloud services like Iron Worker. But I was never satisfied because I wanted something both convenient as well as had nice web UI to be able to have some control - like start/stop/check status of workers as well as see output and error logs. I also didn’t want to run another daemon for this along with my main application and the workers.
I passively searched for a nice solution for years until I realized when we were using gitlab.com runners to run a lot of our CI/CD pipelines and coded up many CI pipelines included multiple steps, often using 3rd party services and bots to control the flow of the pipelines. At the end of the day, a pipeline was a script (or series of scripts or steps) that runs on a runner, in a temporary container in docker/Kubernetes infrastructure. This allows us to use any tool/script language we want, add many environment preparation steps we want, and see the output of the scripts we run.
Gitlab.com CI/CD pipelines support ways to run a pipeline on a schedule without any other trigger (like code push, merge…). This allows us to design our workers as custom pipeline steps and be able to schedule these steps as we want. We can also pass any payload we want from the schedule configuration as a command-line argument to the pipeline scripts.
When I realized this, I experimented with few personal scripts that crawl, extract and aggregates stuff for myself - like a script that processes new craigslist posts through RSS feeds, cache them, and sends notifications on slack. Also, I was able to run these scripts on my own self-hosted runner that didn’t incur any CI/CD minutes. It was perfect.
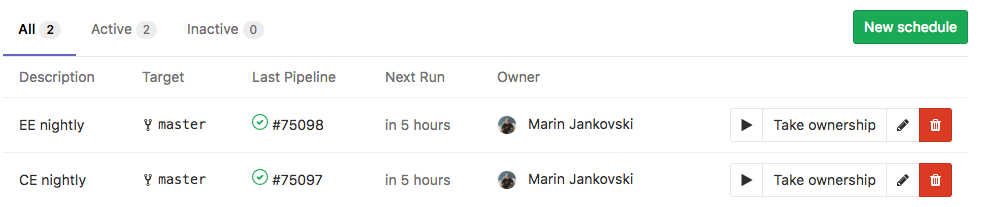
You can design, code, and schedule your background scripts/workers as gitlab.com pipeline steps. Running them on either shared cloud runners (gitlab.com gives 400 minutes per project group per month), or use your own self-hosted runner on a docker swarm (or Kubernetes).
Related Posts
- 6 min readFrom Observability to Action: My DASH 2026 Notes
- 5 min readUsing Vercel (formerly Zeit/now.sh) for super-fast deployments
- 4 min readA Method for Managing n8n Workflows as Code
- 9 min readDurable Queue Workers With Just Postgres
- 5 min readMonitor everything with Healthchecks.io
- 5 min readGitHub Actions and Playwright to Generate Web Page Screenshots
Share