The JavaScript world has come a long way since the early days of XMLHttpRequest. If you’re still using it in 2025, it might be time to consider a change. Let’s break down why fetch() is the modern replacement — and what you should keep in mind when choosing between the two.
A Quick History
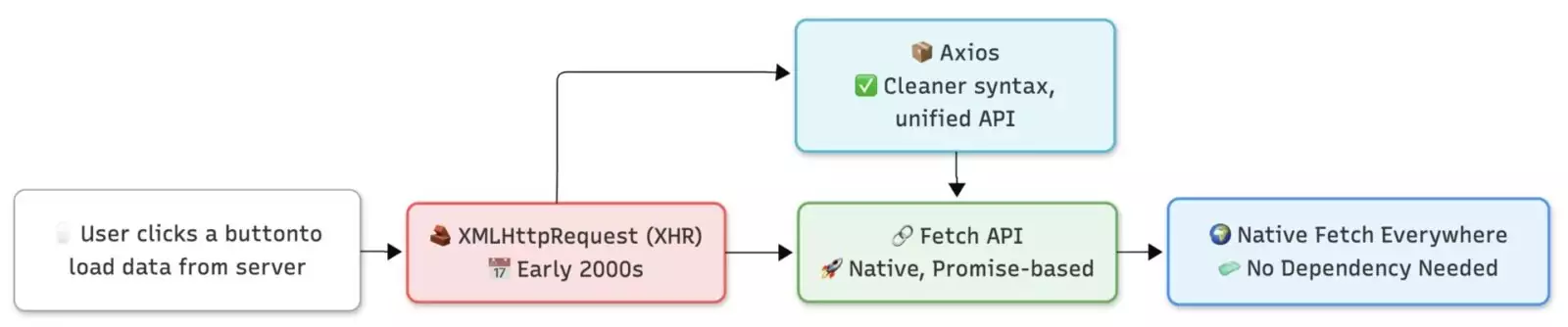
XMLHttpRequest (XHR) was introduced by Microsoft back in the early 2000s and later adopted by other browsers. It was the engine behind early AJAX requests and revolutionized how we interact with web servers.
XHR made it possible to retrieve data asynchronously, but it wasn’t designed with modern JavaScript patterns in mind. Its reliance on event listeners and manual state tracking (like readyState and status codes) can result in more complex and harder-to-maintain codebases.
XHR was revolutionary. It changed everything. It unlocked the modern web and introduced us to a new way of building interactive, dynamic applications.
AJAX EVERYTHING – Boy, we abused it hard.

Then came fetch — a more elegant, Promise-based API introduced as part of the modern JavaScript standard.
Fetch
The fetch() API simplifies network requests. It’s built on Promises, which means cleaner syntax and better support for modern async/await workflows.
Syntax Comparison
Here’s a side-by-side:
XMLHttpRequest Example:
const xhr = new XMLHttpRequest();
xhr.open('GET', '/api/data');
xhr.onload = () => {
if (xhr.status === 200) {
console.log(xhr.responseText);
}
};
xhr.send();
Fetch Equivalent:
fetch('/api/data')
.then(res => res.text())
.then(data => console.log(data));
Cleaner, right?
Feature Benefits
But it’s not just syntax. fetch also offers:
- Request/Response objects for better control and more flexibility
- Stream support for efficiently handling large data responses
- AbortController to cancel requests mid-flight
- Improved CORS support out-of-the-box
- Consistent error handling, unlike XHR which requires extra boilerplate to detect errors
- Support for modern content types like JSON, FormData, and Blob directly
Debugging Advantage
When it comes to debugging, fetch also integrates better with modern developer tools. It’s easier to trace a Promise chain and pinpoint errors than to manually track XHR events and states.
Homecoming to Vanilla
Before fetch became widely supported — both in browsers and in environments like Node.js — developers relied on third-party libraries to abstract and standardize network requests. Tools like axios, superagent, and even jQuery’s $.ajax filled the gap with friendly APIs and consistent cross-browser behavior.
These libraries brought features like request cancellation, automatic JSON parsing, timeouts, and cleaner syntax long before fetch was ready for prime time.
But now that fetch is native in almost all major environments (including Node 18+), there’s less need for external dependencies. If you’re building a modern JavaScript application and aiming to keep things lightweight, fetch fits perfectly into the “vanilla-first” mindset. It helps reduce bundle size and cuts down on unnecessary abstractions — while still giving you the power and flexibility you need.
What to Keep in Mind
XMLHttpRequestis still widely supported and may be required in legacy codebases or certain environments wherefetchisn’t polyfilled.fetchisn’t available in very old browsers, so you’ll need a polyfill if supporting them matters to your audience. But who cares old browsers anymore?fetchdoesn’t reject on HTTP error statuses (like 404 or 500). You still need to checkres.okmanually and handle those cases accordingly.
fetch('/api/missing')
.then(res => {
if (!res.ok) throw new Error('Request failed');
return res.json();
})
.then(data => console.log(data))
.catch(err => console.error(err));
Just use fetch pls
Unless you’re supporting legacy browsers or working with old codebases, go with fetch(). It’s cleaner, Promise-based, easier to read, and aligns better with how modern JavaScript apps are written.
That said — know your environment. Legacy projects don’t always give you the luxury of modern APIs, and that’s okay. Just don’t start new work with XMLHttpRequest unless you really have to.
If you’re building for the future, fetch is the way to go.