I want to talk about a quick tweak you can do in your CDN TTL settings to radically improve your site’s performance. Direct impact on Time-To-First-Byte (TTFB) metric, but as a halo effect, pretty much every other Web Vital.
You can do this in any CDN since TTL customization is a pretty standard need and most CDN providers have easy ways to create rules for various rule configurations.
I use Cloudflare for my blog’s CDN layer. Cloudflare already comes with nice defaults for optimizing the delivery of static assets like images, javascript, css files. But for HTML documents, CDNs use cache-control headers to determine how to cache, and how long to cache. Applications return this header and it’s a way for the application (origin) to tell CDNs how to behave on certain pages. But in this optimization method, we’ll simply override all (or most) of our pages to be highly cached and served from the cache while revalidating in the background.
The way this works is CDN always serves the “last” cached HTML to the reader (or crawler) from the edge network, really really really fast (in some cases double-digit milliseconds), and triggers a request to the origin server to get the “latest” version. Most applications also return proper response codes if the content hasn’t changed from the timestamp that CDN will ask if there is a new update to the content.
How to configure custom TTL in Cloudflare
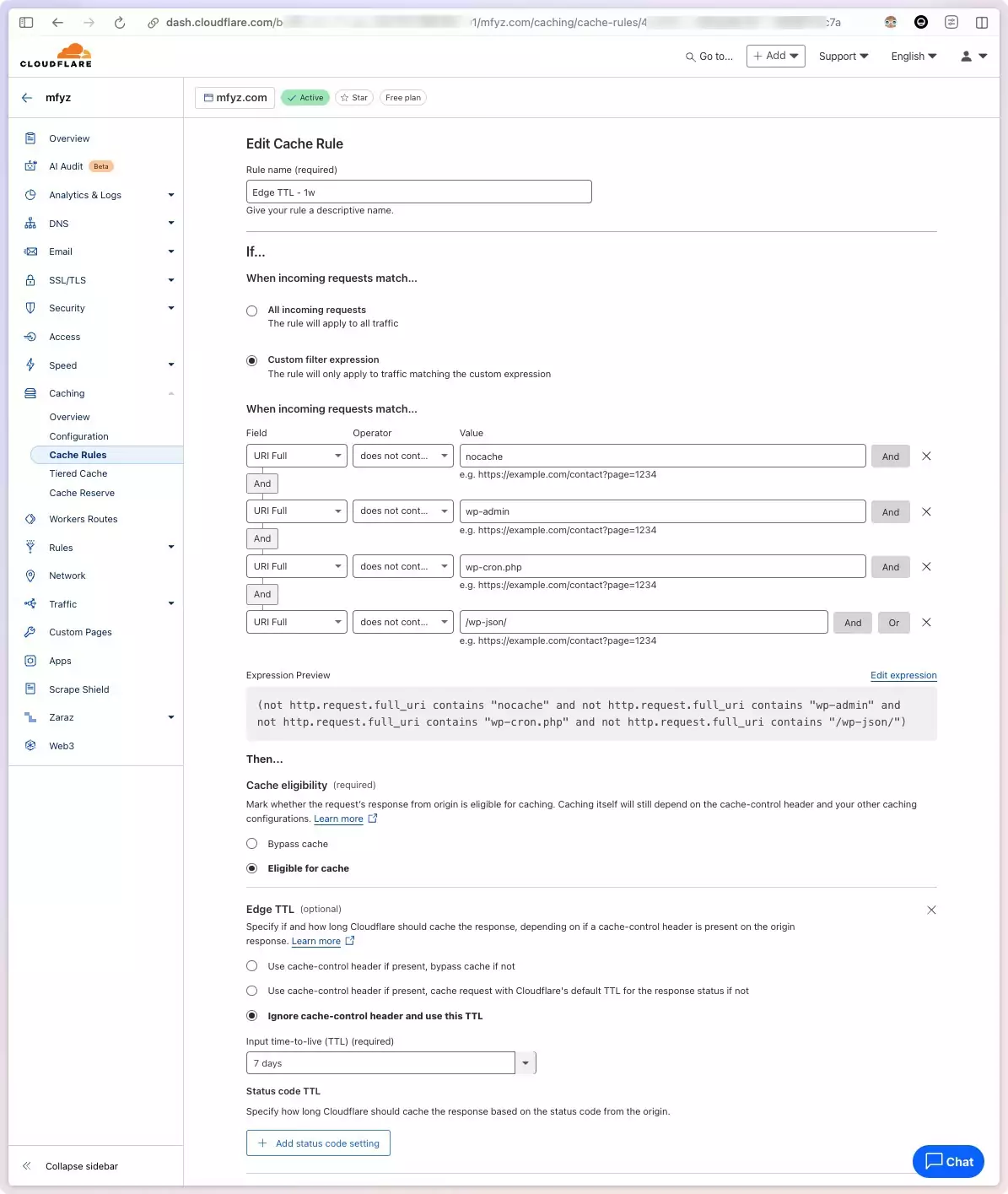
To set up custom edge TTL in Cloudflare, navigate to your site page, Caching > Cache Rules page.
Create a new rule, give it a name, and then set up the request path configuration.
You can set multiple expressions, and exclude patterns that you know are Admin, or Rest API, or other URLs that should NOT be cached long. I use WordPress for my blog and I exclude paths containing things like wp-admin, wp-json, cron…
Then Select “Ignore cache-control header and use this TTL in the Edge TTL section. And finally, select how long you want to cache. Longer is better, because longer means, most of your site content, including long-tail content that doesn’t get consistent traffic will also be cached at the edge. I started with 1 day, then 1 week, then I tried 1 month, but then had some pages stuck in the cache too long, and dialed it back to 1 week as my sweet spot.
Even if you’re not using Cloudflare, I’m sure there is an equivalent of this in your CDN provider.
What is the impact on page speed?
After the change, I saw a big drop (like 90% reduced load) in my server’s load. It meant CDN was doing what it was supposed to do. It’s one of the positive side effects of doing higher cache offload to CDN, to be able to scale higher traffic without needing powerful hosting resources.
My Time-To-First-Byte decreased (improved) 70%, coming from shy of 500ms down to 100-160ms range 🤯
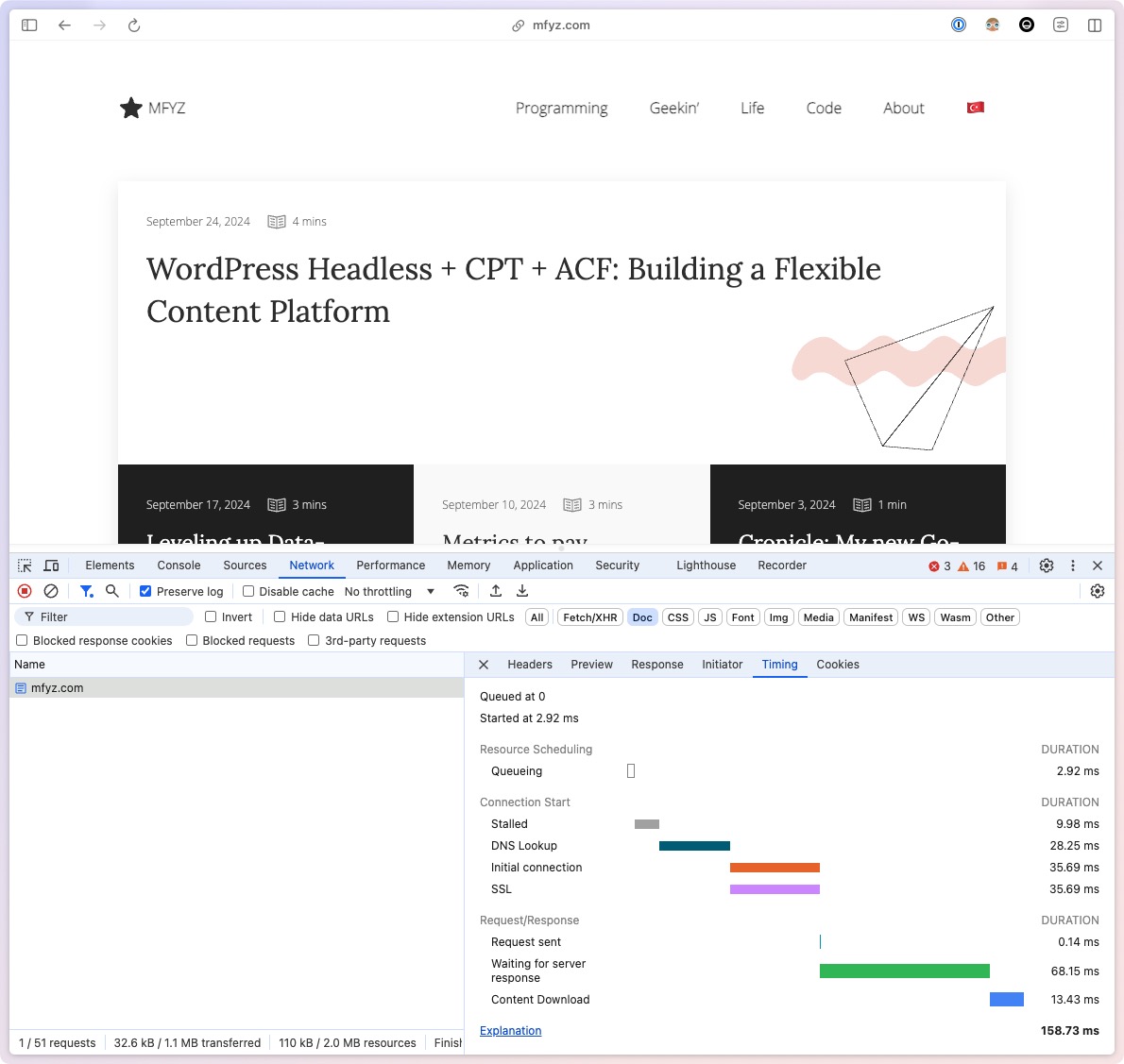
More importantly, the real user experience on the page became even more mind-blowing because things became super snappy. Click click click, bam bam bam, nothing was in a visible loading state anymore. Even if metrics didn’t move, I am super happy with this aspect of the change.
🤯🤯🤩
I got my Cloudflare Web Analytics email and noticed almost all Web Vitals moved positively at least 30% improvement.
I wasn’t expecting other Web vitals like CLS, and LCP to be directly impacted (or impacted as much as they did). But it makes sense. When the assets load much faster like this, the “wait time” (or blocking time) goes down, therefore layout shift or the largest paint goes down.
SEO Impact
It’s well known fact that Google takes your “core web vitals” in account when determining your ranking in the search results. This change has more impact on crawlers than you think. Because most of the time, crawlers’ requests are the ones that hit “cache cold” pages. It means Google (or other search engine) is reading your site holistically way more than your real users. Imagine every single article you wrote. There is no user who reads every single one of them – Google does 🙂 (and does it regularly). When a crawler tries to visit a page that nobody read in a long time, its’ request will have cache-miss more likely than cache-hit, so it will “wait” longer for your web server to render the page.
When you put yourself in the crawler’s shoes, imagine you try to read 10,000 articles/pages on a site over a day or two period (maybe it takes longer, who knows…). Now consider the percentage of those pages that will have to be rendered, or served from the CDN cache. The more pages Google sees “slow”, it will think your whole site is slow.
This is where the real value of super-long TTLs comes in. Especially if you combine that with serve-stale-while-revalidate (SSWR) which most CDNs automatically do (if not, I’m sure there is a setting you can enable these together). SSWR with super-long TTL (like 7 days, or more) basically creates an infinite loop of “always cached” scenarios. And with that, your crawler traffic gets served from the cache (at cost/risk of “stale content” which is OK in the vast majority of use cases), and directly increases your site’s overall speed score and, therefore your SEO scores.
Content Freshness
There is one caveat though, which is content freshness. When you bump the Edge TTL up to multi-day TTLs like I did, you need to make sure your CMS/site is nicely integrated with your CDN’s cache clear systems, in the case you make updates. Two scenarios:
- You update existing content (like fixing a typo, or changing the cover image of a post), the change should be reflected on the content’s detail page right away.
- You publish new content, so the new content is supposed to show up in common places like your homepage.
You can use your CDN’s cache clear UI or APIs to trigger “purge” on URLs you think it’s impacted (homepage, section pages, etc), or highly visible pages like the homepage can be configured with a lower TTL in a separate cache rule set.
I use WordPress for my content management system and Cloudflare has WordPress plugin to listen to publish/update hooks to trigger these cache clear nicely.
Another way to think about this is to find the balance. What is the “stale”ness you can tolerate on a page? Let’s say another article detail page showing “recent articles”, or “related articles” sections to NOT show your most recent article there. As long as that time length is not something you can’t afford, cache longer, to achieve better site/page performance.