We’re creating more bloated digital experiences every day. Worst part, it became the default.
How did we end up here?
In simpler times, we used to simply wrote vanilla javascript, css in another place, assets in another… That’s what browsers (and humans understood really easy).
With the hype of modern frameworks, we came up layers of new dev experience improvements and goodies (don’t get me wrong, I love them), and now we need to transpile our code to something that browser can understand. Transpilation is in essence a simple process (now became too serious… really), but it’s done by what we call “javascript bundlers”. Webpack, esbuild, swc… Their output is (generally), single (or a few) assets that packages and bundles “all” (or most) of your stuff into a few files.

Bundlers can do cool stuff like minification, code splitting, chunking etc. But developers has to train (configure) the bundlers on how to do these. Most of the time developers don’t take time and do this. That results the default output of giant single js, css files.
Bundle everything into single chunk makes sense in some cases. But most of the modern javascript development moved into larger single-page-application behavior even though the user only interacts with a smaller portion of that experience at the end of the day.
This article is essentially an counter point to this default behavior. But I don’t want to focus on the generic code splitting which you should be familiar if you are not, and I’ll touch on a specific aspect of code splitting. I want to call out the other obvious stuff, that can be easily missed by developers which can result even more giant single js and css bundles.
How Often Contents Change Matters
When planning your unbundling, consider how often certain parts of your code will need updates and how frequently you update those parts. Client-side code that undergoes frequent updates, like the main app logic, will invalidate the cache often, leading to more frequent downloads. By separating “set-and-forget” parts, into their own chunks, you minimize unnecessary cache busting. Imagine you make updates to the main parts monthly, but your site/app user visits your app throughout the year and let’s say you’re not making big dependency upgrades. There is no reason anything unchanged to be re-downloaded by your user.
We were just trying to from point A to point B, we kinda ended up overloading:

Let me touch a few obvious things that should be separated from your main bundle. Imagine we’ll start stripping these obvious, less/never-updating parts into its own chunks and at the end you’ll have “the rest” of your bundle that you don’t need to consider every single thing, but these key stuff will help optimizing your site.
1. Binary Assets (Images, Fonts, and Icons)
Including binary assets like images or fonts directly in a JavaScript bundle results in a significant increase in file size, which means longer load times for users. This happens because bundlers like webpack will base64-encode the images or fonts when they’re imported, creating a larger, slower-loading bundle.
To avoid this, use CSS or HTML <link> tags to load these assets. If you’re working with SVGs, consider inlining them in the HTML or creating a sprite file instead of embedding them in JavaScript. Similarly, fonts can be linked through a Content Delivery Network (CDN), letting the browser cache them independently. This way, your assets are handled more efficiently, and your bundle size remains light.
Frameworks and libraries that creating convenience and tokenization like styled components, or other styles-in-js makes this harder because it couples styling into your javascript. Sometimes the references to the assets from these solutions unintentionally includes the binary assets into your js. My rule of thumb is to never enable asset loader plugins in the javascript bundlers which is generally how you enable these libraries to work seamless in your components.
2. Heavy Utility Libraries
a) Use tree-shaken exports
It’s easy to add libraries for utility functions (think lodash or moment.js), but including the entire library when you only need a few functions can be wasteful. These libraries, while useful, often add a lot of code that your application doesn’t actually use.
Instead, try importing only the functions you need. Libraries like lodash support modular imports (e.g., import get from 'lodash/get') so that you only include what you’ll use. Alternatively, look for lighter options or replace certain utility functions with native JavaScript. A lighter bundle with just the essentials will improve loading times without sacrificing functionality.
I previously talked about tree-shaking practice:
b) Consider Code Splitting and Bundling Libraries to vendor.js (or lib.js)
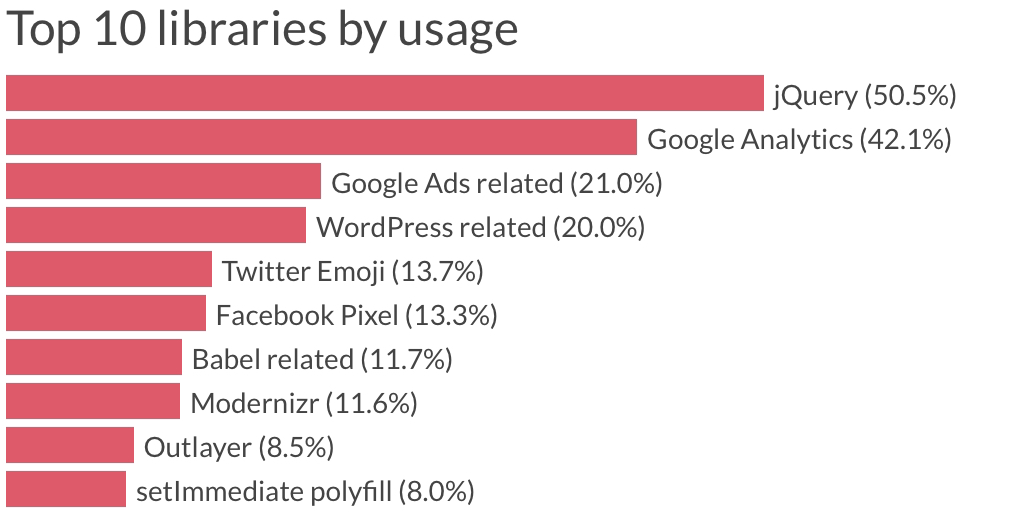
This is probably the most important “obvious” thing that gets bundled in your final javascript bundle and takes up the most space. Your dependencies, libraries you use in your code will most likely stay unchanged (unless you do very frequent updates and upgrades to your libraries – but we often don’t). If you’re not, when you touch single line change on your own custom code, your whole bundle will be re-packaged and create a new single large js file. Even though vast majority of the content of that bundled file is same, the file itself will be completely re-downloaded by your users browser. Consider react.js. It can be around 300kb dependency and it makes total sense to split react itself to its own chunk. Or combine a few (in some cases all) into a lib.js, or vendor.js. This file essentially only need to get updated when you perform updates and upgrades to the included in them.
Most bundler tools have ways to configure and say chunks certain modules into a named chunk you can control.
3. Dev Tools and Testing Utilities
Debugging tools, console logs, and testing libraries are crucial during development but become dead weight in production. They take up space and, in some cases, can expose internal details of your code.
Be sure to configure your bundler to strip out development-only code for production builds. Tools like webpack or environment variables (e.g., process.env.NODE_ENV) make it easy to exclude debugging or testing code from the final bundle. This approach keeps production files lighter and more secure, without sacrificing your development process.
4. Static Data (Large JSON Files or Configurations)
If your project includes large JSON files or configuration data, it might seem convenient to embed these directly in the bundle. But large data structures in JavaScript can significantly bloat file sizes, even though they don’t change frequently.
For a better approach, consider serving static data through a CDN or loading it asynchronously only when needed. If the data is frequently used, you could cache it locally on the client. By removing static JSON or config data from the bundle, you’re allowing for faster initial loads and enabling browsers to handle data separately, making your application feel more responsive.
Keeping your bundle lean is about making thoughtful choices on what to load and when. By excluding binary assets, static data, unused utility functions, and development-only code, you make your application faster, more efficient, and more enjoyable for users. Focus on loading only what’s essential, and you’ll see a big difference in both performance and user experience.
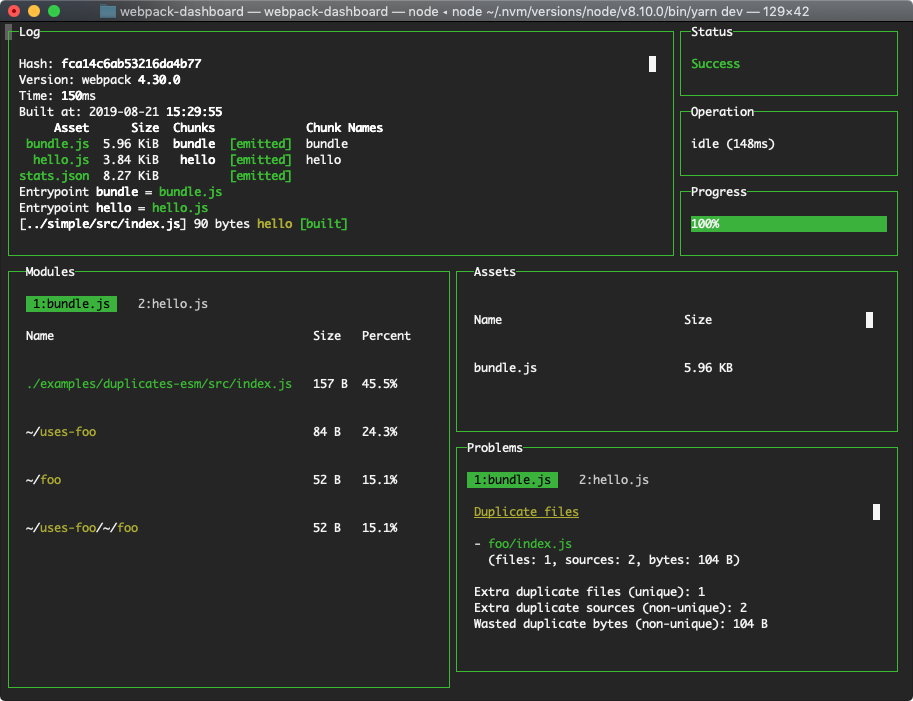
This is definitely not extensive list, but covers a few obvious things to keep in mind. If you use webpack, I previously covered a topic about how to analyze and optimize webpack bundles:





 This is a short explanation of a feature I really like about github and now it’s imitated in bitbucket. Essentially allows you to host a static site under your account.
This is a short explanation of a feature I really like about github and now it’s imitated in bitbucket. Essentially allows you to host a static site under your account.